 StringTable详解
StringTable详解

# 1. String的基本特性
【定义方式】
String str = "abc"; //直接定义
String str = new String("abc");
2
3

String类被
final修饰,不可被继承String实现了
Serializable接口:表示字符串是支持序列化的String实现了
Comparable接口:表示 String可以比较大小
【String底层的变化】
- JDK8及之前是
char value[],JDK9及之后时byte value[]
改成了byte加上编码标记,节约了一些空间
1 char = 2 byte;
一个汉字为一个char,2个byte
# String的不可变性
String:代表不可变的字符序列。即:不可变性。
当对字符串
重新赋值时,需要重写指定内存区域赋值,不能使用原有的value进行赋值。当对现有的字符串进行
连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。当调用 String的
replace方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有的 value进行赋值。
通过字面量的方式(区别于new)给一个字符串赋值,此时的字符串值声明在字符串常量池中
String str = "Hello";
str存储在字符串常量池中,字符串常量池从JDK7开始移到了堆上
【重新赋值】


【连接操作】

【替换操作】



字符串常量池中是 不会 存储相同内容的字符串的
String的 String pool是一个固定大小的 Hashtable,默认值大小长度是1009。如果放进入String pool的 String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后造成的影响就是当调用String.intern()时性能会大幅下降
# 2. String的内存分配
JDK6及之前,字符串常量池存放在永久代
JDK7 将字符串常量池由永久代(方法区)调整到堆内
JDK8 永久代改为元空间,字符串常量池仍在堆上
所有的字符串都保存在堆(Heap)中,和其他普通对象一样,可以在进行调优应用时仅需要调整堆大小就可以了
StringTable为什么要调整位置?
永久代空间默认比较小(使用的是虚拟机内存)
永久代垃圾回收频率低(相对于Eden区的YangGC,Full GC频率低)
# 3. 字符串的拼接
# 字符串拼接细节说明
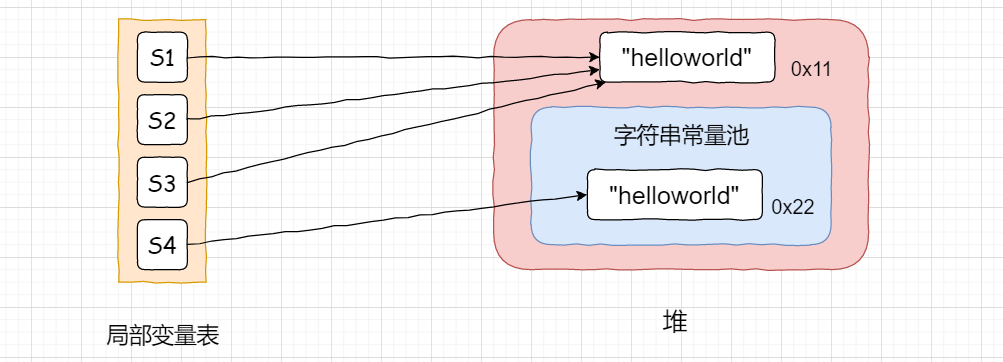
s4到底是怎么将s1和s2拼接起来的呢?

false
s3在字符串常量池中,s4在堆上,二者地址不相同
【s1 + s2操作微观的解释】
javap -v -p反编译查看字节码(要深究具体是怎么实现的,最直观的方式就是查看字节码指令)
this在索引0的位置处

0 ldc #14 <a> //字符串常量池中的"a"
2 astore_1 //存放在局部变量表索引1位置处(当前方法为非静态,0处存放的是this)
3 ldc #15 <b> //字符串常量池中的"b"
5 astore_2 //存放在局部变量表索引2位置处
6 ldc #16 <ab> //字符串常量池中的"ab"
8 astore_3 //存放在局部变量表索引3位置处
9 new #9 <java/lang/StringBuilder> //堆上创建StringBuilder
12 dup //将堆上对象的地址复制到局部变量表中
13 invokespecial #10 <java/lang/StringBuilder.<init>> //init构造器初始化
16 aload_1 //取出局部变量表中的"a"
17 invokevirtual #11 <java/lang/StringBuilder.append> //调用StringBuilder的append方法,将"a"添加apperd("a")
20 aload_2 //取出局部变量表中的"b"
21 invokevirtual #11 <java/lang/StringBuilder.append> //调用StringBuilder的append方法,将"b"添加apperd("b")
24 invokevirtual #12 <java/lang/StringBuilder.toString> //toString()转为字符串,"ab"
27 astore 4 //"ab"存放在局部变量表索引4位置处
29 return //返回
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
此处,我们也可以再次清晰创建对象的三步骤:

间接说明
new关键字不是原子性的
在堆上分配空间创建对象
局部变量表存储对象地址的引用
dup指令构造器初始化
<init>
【dup指令简介】:
查看字节码指令的时候,可以看到每个new指令之后都会跟一个dup指令。
因为new指令之后紧跟着就会调用指 invokespecial行初始化:下面是 invokespecia的指令格式。看一下操作数栈,需要一objectref彐用(对象的地址),后面是可选的数;由于初始化没有返回值,调用之后没有东西入栈(用…表示没有入栈)

dup指令就是将当前对象在堆内存上的地址复制一份到局部变量表中。也就是说初始化指令会使当前对象的引用出栈。如果不复制一份,操作数栈中就没有当前对象的引用了,后面再进行其他的夭于区个对象的指令操作时,就无法完成。
https://www.zhihu.com/question/52749416
【s1 + s2操作宏观的解释】
首先创建StringBuilder对象StringBuilder sb = new StringBuilder();
sb.append("a");sb.append("b");sb.toString();//new String 返回字符串"ab"
就是将字符追加到StringBuilder的字符缓存区内,然后通过toString()返回该字符串
【拓展】
字符拼接操作不一定使用的是StringBuilder
如果是常量引用,被final修饰,如果拼接符号左右两边教是字符常量或常量引用,则仍然使用编译期优化,非StringBuilder的方式


总结来说,字符串的拼接就这四句话:
- 常量与常量的拼接结果在常量池,原理是编译期优化
- 常量池中不会存在相同的内容
- 只要其中一个是变量,结果就在堆上的非字符串常量中,拼接的原理是StringBuilder字符缓存区
- 拼接结果调用
intern()方法,将字符串常量池中没有的对象放入,返回该对象的地址
常量或者被final修饰的变量,在编译器可以确定,所以存放在常量池中
变量由于其引用的地址不确定,所以不能放入常量池,在堆上创建
# 面试题测试

显然,都为true

在编译完的class文件中,s1和s2是相同的,说白了s1就是语法糖
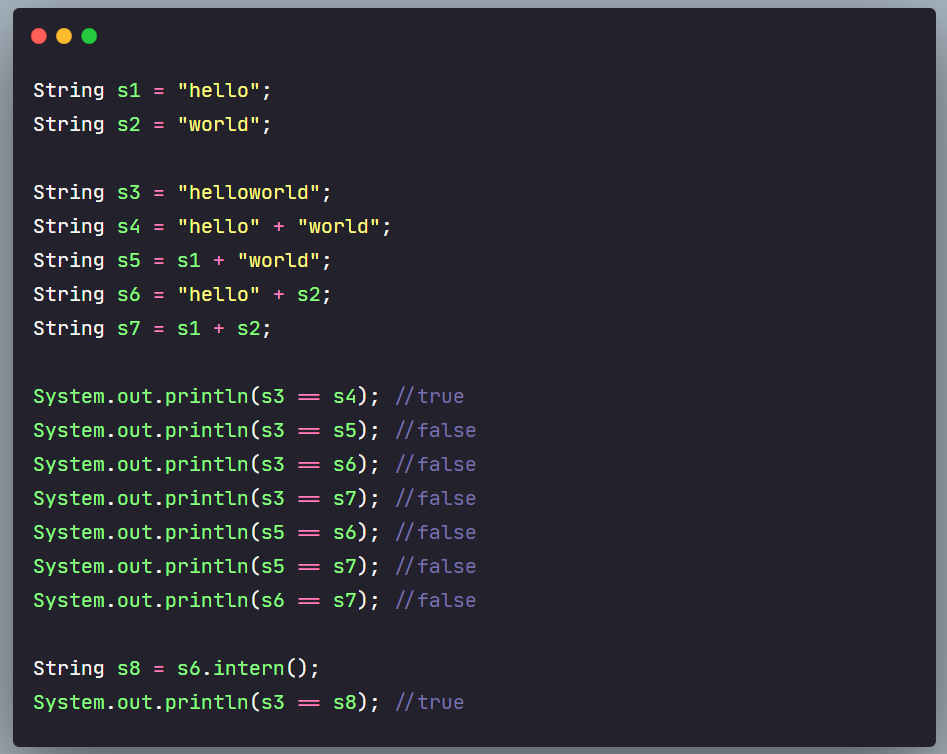
String s5 = s1 + "world"; //此时,s1相当于变量
如果拼接符号的前后出现了变量,则相当于在堆空间中new String(),new 出来的存放在新生代(一般情况),具体的内容为拼接的结果
String s8 = s6.intern();
System.out.println(s3 == s8); //true
2
intern()方法校验字符串常量池中是否存在helloworld
不存在,则创建一个
存在,则返回该字符串的地址

# 效率对比
测试StringBuilder与字符串+的效率对比:

test_StringBuilder(); -- 2ms
test_String(); -- 8897ms
字符串+的操作效率低下的原因就是:
每次循环时都会创建StringBuilder和String对象,相当于每次都有两个
new操作使用Sting的字符拼接方式:内存中由于创建了较多的StringBuilder和String的对象,内存占用更大;如果进行GC同样会耗费时间
# 4. intern方法
【JDK8 文档描述】

如:
String str = new String("Hello world").intern();
调用intern()方法来创建字符串时,先到字符串常量池中找有没有与要创建的字符串str
equals相等的串target
如果有,则返回字符串常量池中target的地址引用
没有,则创建str到字符串常量池中,返回str的地址
如何保证变量s指向的是字符牢常量池中的数据呢?
方式一:String s = "Mr.Q";字面量定义的方式
方式二:调用intern()方法
# new String的讨论
【讨论一】
String s = new String("ab");
new String("ab")为什么会创建两个对象?
查看字节码指令:

在堆上创建了一个
在字符串常量池中创建了一个(常量池之前没有的话)
new String("a") + new String("b")呢?
- 对象1:
new StrintBuilder() - 对象2:
new String("a") - 对象3:字符串常量池中的
"a" - 对象4:
new String("b") - 对象5:字符串常量池中的
"b" - 对象6:
new String("ab")
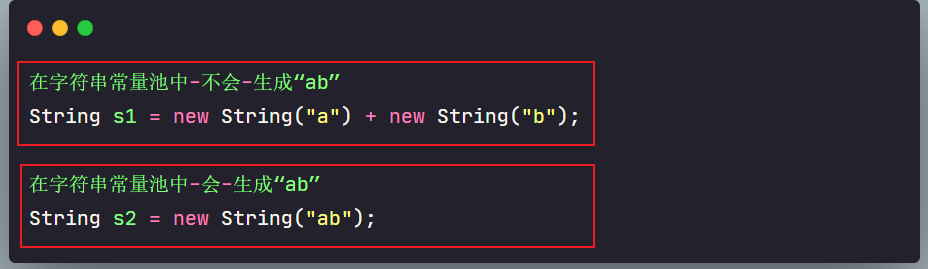
【深入剖析】
StringBuilder的toString():
toStirng()的调用,在字符串常量池中,并没有生成"ab"
解析接着看下面娓娓道来😈
【讨论二】
【s1和s2的分析】

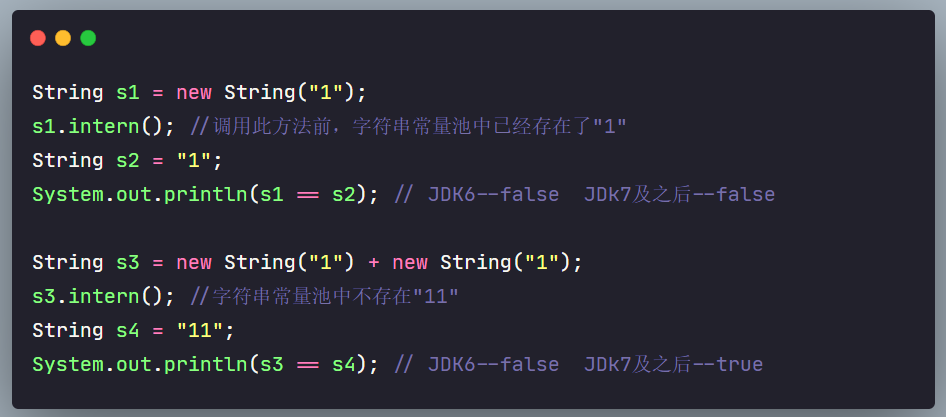
无论什么版本的JDK,s1创建在堆上
调用
intern()方法,拷贝一份到字符串常量池中,s2记录的是字符串常量池中11的地址二者存储的位置不同,自然是false
【s3和s4的分析】
s3记录的地址为堆空间上(非字符串常量池中)
11的地址s4请看下面解释(要说清楚牵扯的东西还有点多....)
问题的关键是此时字符串中是否存在11呢?
new String("1") + new String("1");创建完字符串对象,append()拼接完,在toString()返回的时候,其实在字符串常量池中并不存在"11"
根据上面的【讨论一】我们知道,在new String()时其实是创建了两个对象
new了两次之后再append(),那么在字符串常量池中为什么没有呢?我们需要查看一下StringBuilder的toString()源码的字节码指令
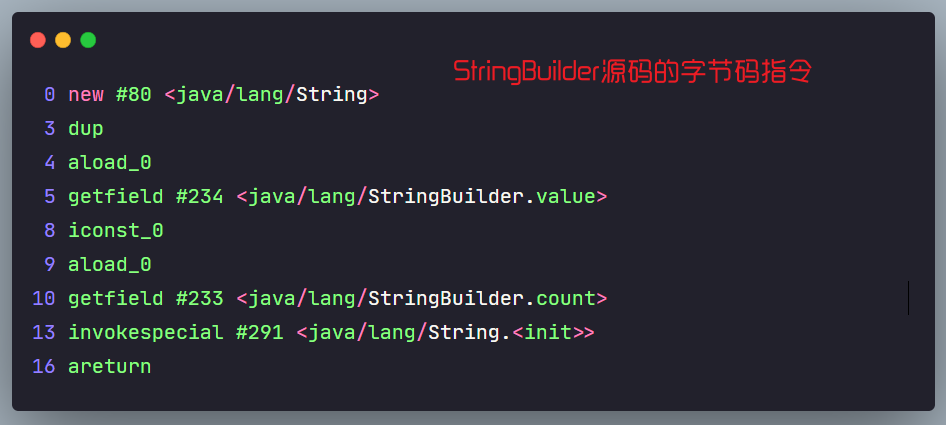
我们发现并没有ldc指令,其实就拼接完没往常量池中放一份
可是,为什么JDK6和7会出现不同的答案呢?
因为JDK6的字符串常量池在永久代中,不在堆上,它会在常量池中新创建一个对象,就会有新的地址,这就回到了s1和s2的问题了,是false
JDK7及之后字符串常量池虽然在概念上是属于元空间的,但是其实真实的位置是在堆上的
【真实情况是这样的✔】
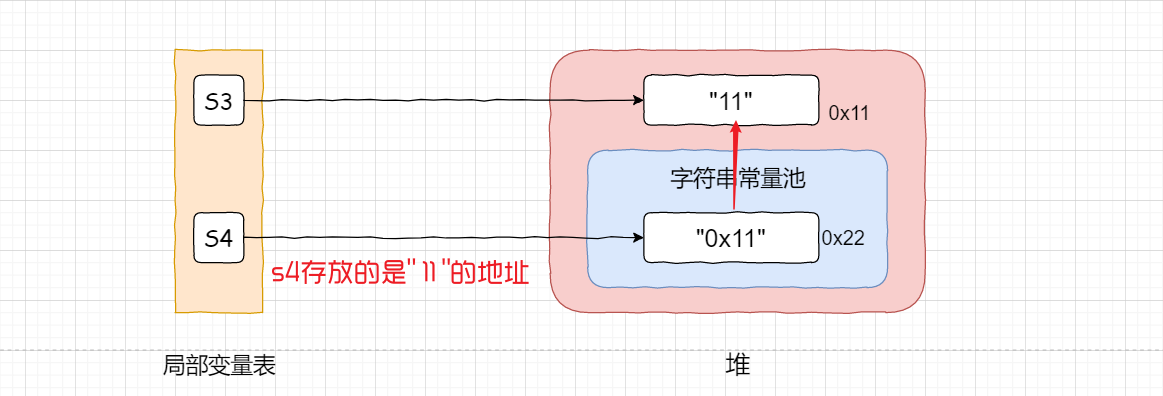
String s4 = "11"; 使用的是上一行代码s3.intern();执行后,s4变量记录的常量池中生成的”11”的地址
🙃换句话说,图省空间,池子里没新创建,池子里引用的是已经在堆上创建了的11的地址
【总结一下📔】

JDK7:此时字符串常量中并没有创建11,而是创建一个指向堆空间new String("11")的地址
# 拓展

此时,11这个字符串对象在堆空间上和字符串常量池中各有一份,地址不相同
# intern总结
总结String的intern()的使用:
String s = new String("a") + new String("b");
s.intern();
2
JDK6 中,将这个字符串对象s尝试放入字符串常量池
如果字符串常量池中有,则并不会放入。返回已有的串池中的对象的地址
如果没有,会把此对象复制一份(深拷贝),放入字符串常量池,并返回字符串常量池中的对象地址
JDK7 起,将这个字符串对象s尝试放入字符串常量池
如果字符串常量池中有,则并不会放入。返回已有的字符串常量池中的对象的地址
如果没有,则会把此对象的引用地址复制一份(浅拷贝),放入字符串常量池,并返回字符串常量池中的引用地址
结论:对于程序中大量存在的字符串,尤其存在很多重复字符串时,使用 intern()可以节省内存空间